「研究発表のためのスライドデザイン」を流し読んだ
スライド作りについてよさそうな本があったので流し読みました。
「研究発表のための」とあるように、きれいでおしゃれなデザインの話ではなくて、必要な情報を的確に伝えるという意味でのデザインの本です。
概要
- 第1部 「わかりやすい」スライド構成にするために
- 第2部 「わかりやすい」スライドを作成する技術
- 第3部 スライド全体の構成を聴衆に伝える工夫
構成はこうなっていまして、わかりやすいとは何か?を定義するところから始まっています。研究っぽくてすてき。
トピック
スライド作成技術の内容としては「1スライドに1メッセージ」や「簡素に」といったスライドデザインの基礎的な話ももちろんありますが、読み進めていくといろいろと踏み込んで解説しているところもあり、「あ・・・自分のスライドだめだ・・・」みたいになるところもありました。
いくつか紹介しておきます。
イラストレーションのためのステップ
伝えたい文章をイラスト・図にするためにどういうステップを踏むとよいかの解説。
キーワードの抽出や分類と相互関係の抽出、それを表現するための図示のサンプルなど、非常にわかりやすく説明されています。
わかりやすいかチェックリスト
わかりやすいスライドの評価軸が示されており、自分のスライドにどういう問いかけをして改善していけばよいかのヒントになります。
このあたりのトピックはほんのキャプチャを載せたいぐらいの気持ちになりますが、それはダメなので気になる方は書籍をどうぞ・・・。
まとめ
研究のため、とありますが、仕事や学校の中でスライドを使った説明をするときに意識すべきことが詰まっています。
スライドを作っていくうえでの自分で読むバイブルとしての側面もありますが、どちらかというとスライドをこれから学ぶ人に「良いスライドはどう作ればいいのか?」という疑問をぶつけられた際に教科書にするような本、というイメージがしっくりきました。「伝わるスライドってこういうことだよね?」と議論しながらスライド作成する際にぜひどうぞ。
「AI DRIVEN -AIで進化する人類の働き方-」を流し呼んだ
「AI DRIVEN -AIで進化する人類の働き方-」を流し読んだ。
生成AIが社会に与える影響を簡単な言葉でわかりやすく描いた本。生成AIの仕組みだったり技術を解説するものではないです。
活用の仕方や、仕事の中のどんな場面で活用できるかというケーススタディーを得るのに良さそう。
概要
章立て:
ジェネレーティブAIの到来で変わる世界
第1章 働き方――仕事はDJ的なものになる
第2章 学び方――必要な学びを個人が選択する時代
第3章 イノベーション――創造は「0から1」でなくなる
第4章 組織づくり――リーダーシップとは「人間を見る力」になる
第5章 新時代をサバイブするAIリテラシー
ピックアップ
1章より:AIで変わる仕事
営業や事務・マーケターなど、仕事の種類ごとに実際にどのように生成AIを活用できるかを紹介している
この部分だけなら色々なWebなどで言われているようなことではあるが、ここから先の章でどう注意すべきか・将来どうなっていくかが論じられるのでそのスタートとなる地点
2章より:AI時代の調べる技術
「ChatGPTに疑問を聞く」ということは一般にやられていると思うが、向いている質問・向いていない質問・ミスを起こす実例などがまとめられている
断定口調で間違いを言う
間違いを指摘しても、更に間違いで上塗りする、など
正解を教えてもらうものではなく、きっかけやとっかかりとしての使い方に使うこと、またそこから発展して主体性を身につける教育の話にも触れる
4章:AI+DAOで実現する「フェアな組織」
筆者の伊藤穰一さんといえばweb3の分野でも第一人者なので、web3とAIの話も載っているのが特徴的なところ
総括
一貫して、生成AIの「間違う」「悪気のない嘘をつく」ということをちゃんと認識した上で、仕事のアシスタントとしてうまく使うことを説いた本
人間が担うべき部分というのを認識して生成AIとうまく共存しよう
「イノベーションのジレンマ」を流し読んだ
今回は言わずと知れた(?)有名本、イノベーションのジレンマを読みました。
この本は大成功を収めている優良企業が、気がついたら新しい技術を持った新興企業に押されてイノベーションに置いていかれてしまうのかについて、過去の事例や研究を基に理論的に解明していく内容です。
ざっくり概要
優良な大企業が新興企業に飲み込まれてしまう要因としては 「拡大のため優れた経営をし、顧客や市場と向き合い、技術を高めていく」からこそ、失敗するというジレンマを抱えていることがまとめられています。
本書ではハードディスク業界の事例などを交え細かな事例もふんだんに載っているのでここではポイントだけ。。。
持続的な成長と破壊的イノベーション
イノベーションのジレンマを紹介するとき、まず語られるのはこのポイント。
すでにある市場ですでにある製品を改善し、ニーズに応えていく持続的な活動と、まだ市場すら曖昧で技術的にも甘い(が、結果として今後既存市場を塗り替える)部分に切り込んでいく破壊的イノベーションは全く異なるもので、持続的な成長のための戦略はイノベーションの前ではむしろ逆効果になる。
大企業にとって、破壊的イノベーションは最初は無視できるレベルの小さな市場と技術から始まるが、その技術レベルやコストが新たな市場を生み出し顧客のニーズを満たし始めた頃にはもはや手遅れになっている。
組織能力
特定の領域・特定のバリュー・ネットワークで磨かれ、専門化された組織や組織の技術は新しいやり方に簡単に転移できない。
技術だけでなく利益の構造(どれくらいの規模受注し、どれくらいの利益を上げれば良いか、など)も対応できない。
資源マネジメント
破壊的イノベーションを前にしたとき、「市場を分析し見極めて適切に資源を配分・・・」というやり方はできない。そのような情報がないため。
持続的な成長の段階では引き締めるべき「失敗」に寛容になるよう必要がある。
また、企業としてはより高い収益や基盤の安定を目指して上位の市場へ向かう力が働くがイノベーションはその逆のより収益が見込めない部分に着目せねばならず、どのように向き合うのか(コスト・資源を注ぎ込むのか)考えなければならない。
感想
内容としては上でまとめたポイント以上に細かく語られていますし、ポイントも結構無理矢理まとめた感があるので、興味のある方はご一読を。
ただ、ディスクドライブや掘削機の例が細かく載っており、それ自体に興味がある人ならともかく、あまりイメージ持てない人にとっては、ジレンマの説明の前に事例の部分で頭の中が「???」になる可能性あり。
また、この記事では触れていませんでしたが、このジレンマにどう対処していくかの話もあります。
明確な答えは書籍にも世の中にもないとは思いますが、スピンアウトして対応した成功事例などいくつも各社の対応が載っているため読み応えがあると思います。
まぁ経営者の一種のバイブル本だと思いますので、私がおすすめするまでもなく必要は人は読んでいることでしょう。
--
『「組織のネコ」という働き方』を流し読んだ
「「組織のネコ」という働き方」を流し読みました。
イラストかわいいなぁと思って読み始めました。(あと言わんとしてることにも色々心当たりが。)
ものすごく要約すると
組織の中心を志向する「イヌ型」、組織にいながら自由を志向する「ネコ型」それぞれの考えや相性、それぞれのキャリア、組織づくり(特にネコ型の扱い)について実例を交えてまとめたもの。
また、意識的にも無意識的にも犬の皮を被ったネコになっている人へのメッセージ。
章を紹介すると
- 働き方の4つのスタイル
- 組織にいながら穏やかに働く
- 型破りな成果を上げる人の共通点
- 進化のカギは「よい加減」
- 組織の変人が変革人材になる
- 自立型の組織をつくる
書き方も適度にゆるいのでサクサク読める系の本です。
4スタイル+α
まずテーマの中心にあるのが志向と能力で4スタイルに分けるもの。
- 縦軸:パフォーマンスの高い/ふつう
- 横軸:組織の中心を志向/自由を志向
により4つに分類します。(図は本の表紙を参照)
それぞれがライオン・トラ・イヌ・ネコです。
そしてネコの部分には、本来はネコだがイヌの皮を被ったネコがいるとしており、そこの層に向けたメッセージが中心となっています。
サブタイトルの
「組織のイヌ」に違和感がある人のための、成果を出し続けるヒント
というのがそういう意味です。
書籍の中にもタイプを診断するネコ度チェックリストというのが出てきますが、自分がどのタイプか考えながら読むと楽しいです。
おすすめ読者
「こういう働き方をやれ」とか「ライオン・トラになれ」みたいな本ではないです。それぞれの生態を解明していくというイメージです。 なので、メインターゲットの
- 自分は組織に違和感のある隠れネコかもしれない
と思う人はもちろん
- なんか最近の若者の価値観、自分達と違ってね?
とか
- どうもいうこと聞かない人がいて困ってる。(逆にむしろもっと自由にやっていいのに。)
みたいに、組織をつくるうえで人の動き方や考えをより理解したい人にもいいのではないかと。
私的な感想
自分はもう読む前から圧倒的ネコ型だと思ってたので、「うんうん、そうそう」と思いながら読んでました。
で、むしろ逆にイヌ型の人ってそんなに多いの?というのは常々思っていたので、そっちの志向を理解をしなきゃなぁという感想。隠れネコが大半だと思ってた。
--
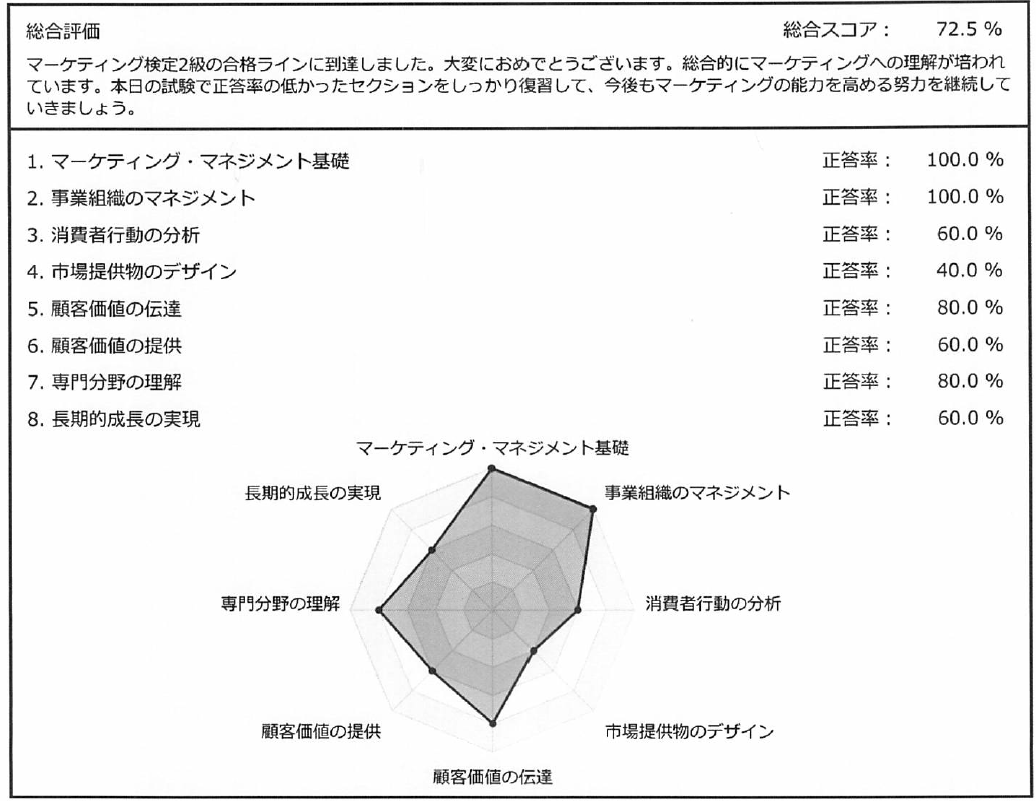
3級に続いて「マーケティング検定2級もやってた」 結果
さて、2022年の年始明けに「マーケティング検定2級」受けてきました。
受けるまでのお勉強についてはこのシリーズをどうぞ。
まずは結果から。。。
こんなブログを書いているわけですからなんとか恥ずかしくない結果を出したいところ。。。
結果
合格!
ギリギリじゃないですかー!!
ひとまずホッとしてはいますが、感覚としては不合格でも不思議じゃなかったなぁという感じ。。。
2級の印象総括
- まず、公式の書籍がとても良い。試験対策というよりマーケティング全体を網羅した参考書籍として優秀。
- マーケティング専門外の人にとっては最低限以上の十分な知識が得られると思う
- マーケティングの全体像が掴めるかつ各領域の概要や歴史的な背景がわかる
- マーケティング専門の人にとっても基礎知識を得たと言える程度の知識にはなるのではないかと
- たとえばマーケ会社の新卒〜3年目程度ぐらい
- ただしそもそも私が専門外なのでこれは推測です
- 業務への直接的な活用という面では、実践経験が必要な印象
- 実践編というよりは、学問としてのマーケティングという印象
- これを理解した上で実践的なマーケティング本読むとかなり良いのでは
(おまけ)振り返り
勉強時間
今回は1ヶ月程度勉強期間を取りました。
時間にすると、50~60時間程度と思います。
公式本を先頭から読んでまとめて読んで、、、を繰り返していました。
こんな感じでメモが積み上がっていきました。
しっかり用語を暗記というよりは、ざっと流れを理解していく感じでやっていきました。ただし試験に受かるのが目標の場合は、出てくる単語とかもしっかり覚えておく方がよいです。結構専門用語がポンポン問題文に出てきます。
難易度について
3級に比べるとだいぶレベルアップしている印象です。
選択肢も3級にもまして絞り込みにくくなっています(日本語の流れ的にこれはない、みたいなのはほとんどなかった印象)
前提知識なしから勉強するとなると、おそらく100時間ぐらいの勉強時間を必要とする試験かなと。
参考までにですが、直前に公式問題集の問題部分をざっとやり直すと88点でした(まぁこの本で勉強したので高得点にはなりやすいですが)、それが本番では72点です。
どんな人におすすめ?
「知識としてマーケティングを知っておきたい」という場合は3級ぐらいまででよいかも。
一歩進んで、「マーケティングの基礎を広く抑えた上で何かに活用したい(仕事で使いたいとか、マーケ施策を考えたいとか)」という目標がある人にとっては勉強する価値のある検定かと思いました。
--
3級に続いて「マーケティング検定2級もやってみる」 その3
サプライチェーン・マネジメント
- マーケティングチャネル(物流・情報流・商流)
- 直接流通(ダイレクトマーケティング・直接販売)
- 間接流通(市場取引システム・垂直的流通システムVMS)
- 在庫回転率
- 多頻度小口化
- 延期と投機の理論
顧客関係マネジメント
- CRM
- 取引コスト、機会主義的行動、資源依存理論
- 顧客生涯価値LTV、クロスセリング、アップセリング
- カスタマーエクイティ(バリュー・ブランド・リレーションシップ)
サービス・マーケティング
- サービスの特性(無形性・生産と消費の不可分性・品質の変動性・消滅性)
- サービスデリバリーシステム、真実の時間
- SERVQUAL(触知性・信頼性・反応性・保証性・共感性)
生産財マーケティング
- 生産財の分類(部品・原材料・設備・業務用供給品・サービス)
- 組織購買
- 意思決定プロセス
- イノベーションのジレンマ
ソーシャル・マーケティング
- 企業の社会的責任CSR
- コーズプロモーションとコーズリレーテッドマーケティングCRM
- 環境マーケティング、グリーンコンシューマー、グリーンサプライチェーンマネジメント
- ソーシャルマーケティング(非営利組織、社会志向)
- サステイナブル・マーケティング志向
- SDGs、ESG
グローバル・マーケティング
- 配置(参入市場・参入モード)と調整(標準化・現地化・知識移転)
- 参入モード(間接輸出・直接輸出・ライセンス供与・ジョイントベンチャー・直接投資)
- グローバル・ポートフォリオ(市場魅力度、競争上の優位性、市場間の相互連結度)
- 近代的流通MT、伝統的流通TT
やっとまとめおしまい!
次回は結果と感想です。
3級に続いて「マーケティング検定2級もやってみる」 その2
では続きの列挙です。
消費者行動の分析
消費者視点でみた購買の意思決定に関する話です。
どのように情報を記憶したり処理したりするかという話まで踏み込んでいてなかなか興味深かったです。
- 7つのO
- 消費者行動の外的要因、内的要因
- ライフサイクル・ライフスタイル・ライフコース
- 家計内生産と時間コスト
- CDPモデル(購買意思決定プロセス)
- 情報処理メカニズム
- 想起集合、カテゴリー知識構造、連想ネットワーク、スキーマ、スクリプト
- マーケティングリサーチ
価格デザイン
- 価格感受性、価格弾力性
- 価格設定方法(顧客価値ベース・コストベース・地理的価格設定・アローワンス・差別型価格設定・心理的価格設定 など)
- 競合他者による価格変更への対応
- 無視、適応、反撃、防御価格デザイン
製品開発と顧客価値
- 中核ベネフィット、実態部分、付随部分
- 便益の束
- 組織デザイン、逐次的プロセス、並行的プロセス
- 製品ライフサイク、イノベーション普及理論
- スタイル、ファッション、ファッド、計画的陳腐化
- コモディティ化の促進要因・対応
- 経験価値マーケティング
- 戦略的経験価値モジュールSEM
- 経験価値プロバイダー
ブランド・マネジメント
- ブランドの役割、価格プレミアム効果、ロイヤルティ効果
- ブランド機能(保証・識別・共起)、ブランド拡張とライセンス供与
- ブランド認知(再認、再生)、ブランド連想
- ブランドエクイティ
- ブランドの基本戦略(強化・変更・リポジショニング・開発)
- ブランド拡張戦略(ライン拡張・カテゴリー拡張)
- ブランドビルディングブロック
- レゾナンス、ジャッジメント/フィーリング、パフォーマンス/イメージ、セイリエンス
マーケティング・コミュニケーション
- 広告、販促、イベントと経験、パブリシティ、人的販売、DM
- 消費者反応プロセス
- 目的:製品カテゴリへのニーズの認識、ブランドへの認知、ブランドへの態度形成、ブランドへの購入意図と購買行動の形成
- 予算設定方法(支払可能額法、売上高比率法、競争者対抗法、目標基準法)
- 販売促進の類型(流通業者向け・消費者向け・小売業者)
これでもだいぶ削っている。。。